Rendering mode was the wrong axis
Table of contents
Update, 2026-05-22: Layer 3 has since shipped as a dual-beacon setup, and Anthropic IP-range verification was retracted after the published ranges turned out to describe API/MCP egress, not crawler egress. The current methodology page reflects the live tracker.
When a client comes to me with “we migrated to Next.js and suddenly half our pages are missing from ChatGPT search results”, they never — not once in twenty-five years of doing technical SEO — phrase the problem as “did you pick the wrong rendering mode?”. They phrase it as “the product price isn’t there”, or “the article body shows up empty”, or “navigation links don’t seem clickable to bots”. They’re describing a content pattern, not a rendering mode.
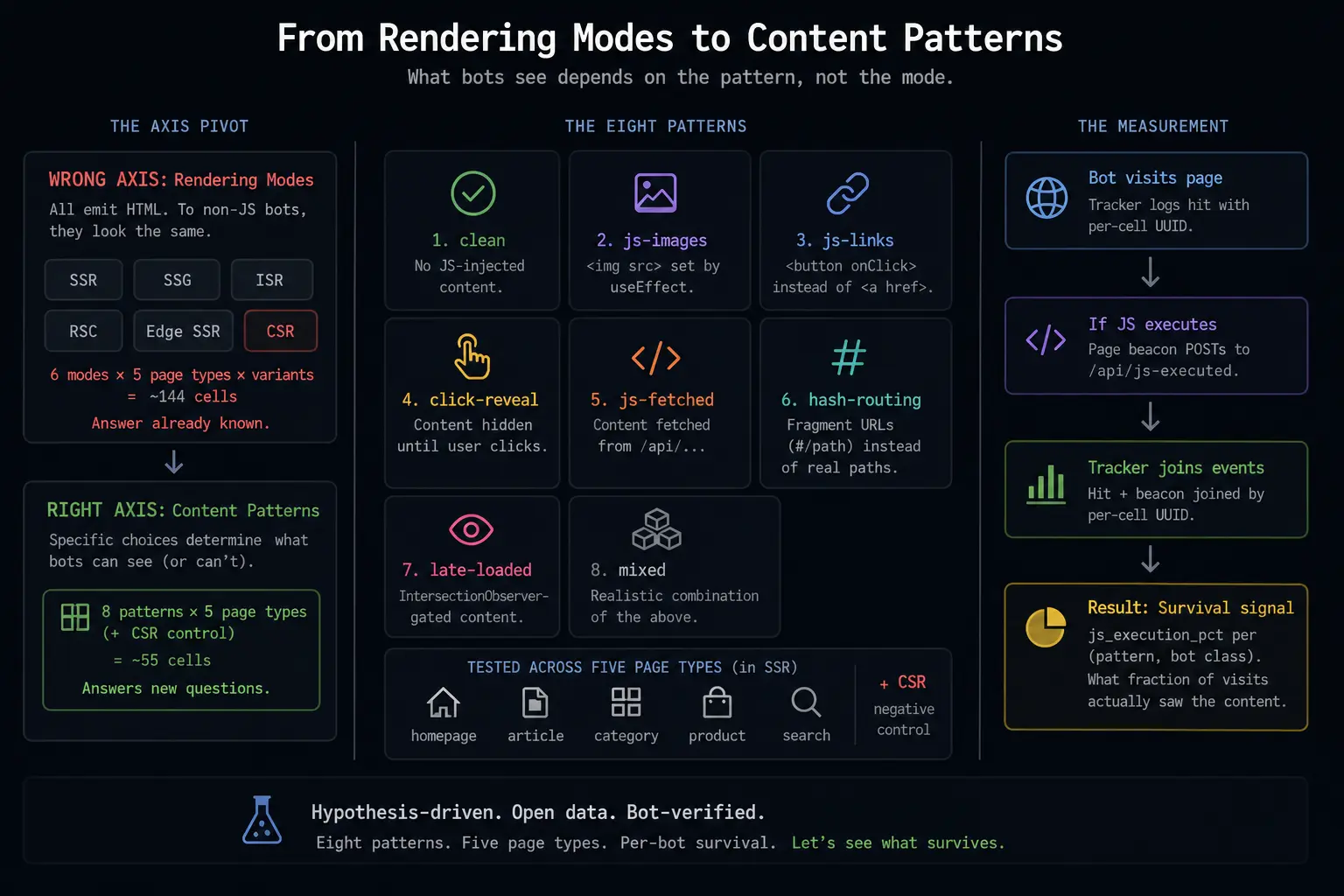
I spent the first weeks of this project building a test bed around rendering modes anyway — SSR, SSG, ISR, RSC, CSR, Edge SSR — because that’s how the public literature frames the question. Six modes × five page types × variants × image patterns = ~144 cells to populate. A lot of infrastructure work for a question whose answer was already in print.
So I deleted it and started over.
What Vercel and MERJ already settled
The 2024 Vercel + MERJ piece The Rise of the AI Crawler is the single best public data point on this question. They instrumented billions of requests across the Vercel edge and measured what AI crawlers (GPTBot, ClaudeBot, PerplexityBot, plus Googlebot for comparison) actually fetch, what they render, and what they ignore. The headline finding: batch AI crawlers don’t execute JavaScript. Not “rarely”. Not “with some delay”. They don’t execute it at all.
GPTBot fetches .js files in about 11.5% of requests. It doesn’t run them. ClaudeBot fetches them in about 23.8% of requests. Same story. PerplexityBot, Bytespider, CCBot, Meta-ExternalAgent — the entire batch-crawl population reads HTML, ignores scripts, moves on.
Once you have that finding, the rendering-mode question becomes trivial. SSR, SSG, ISR, RSC streaming, Edge SSR — all five emit static HTML in the first response. To a non-JS bot, they’re indistinguishable. Only CSR is different, because the server returns an empty shell and the content arrives client-side. For batch crawlers, all server-rendered modes look the same.
If I had run my original 6-mode experiment, I would have measured this on a new domain, with my own dataset, and published “we confirm Vercel/MERJ at mode granularity”. Replication has value. But it’s a known answer, and confirmation isn’t what most clients need.
What real audits actually ask
Sit in on any technical SEO audit of a JS-heavy site and you’ll hear these questions:
- The product page renders fine in my browser, but the price doesn’t show up when ChatGPT browses it. Why?
- We added click-to-reveal sections for FAQ content. Did that just become invisible to Google?
- Our category pages fetch the item list client-side after mount. Are we indexed?
- Navigation uses
<button onClick={navigate}>instead of<a href>because the design team wanted hover animations. Does that break crawl? - We have an IntersectionObserver lazy-loading product cards. Where do those go in the index?
None of these are “rendering mode” questions. They’re content pattern questions — specific decisions the engineering team made about how a piece of content gets into the user’s browser, layered on top of whatever rendering mode the framework happens to use.
In Next.js terms, the same SSR page can contain:
- a
useEffect-fetched<img src>that’s empty in the initial HTML - a navigation
<button>that’s not a real<a href> - a “Show more” gate hiding the article body until click
- a
fetch('/api/...')powering the price in a product card - a hash-routed sub-navigation (
#/tab-ainstead of/tab-a) - an IntersectionObserver gating a related-articles block
Mode is SSR for all of these. Every cell would have looked identical in my original experiment. The thing the bots see — or don’t see — depends on the pattern, not the mode.
The eight patterns
I narrowed it down to a catalogue of eight. They’re the patterns I see most often in real audits, and they’re distinguishable enough that the visibility signal per pattern is interpretable on its own:
- clean — no JS-injected content, the baseline.
- js-images —
<img src>set byuseEffectafter mount. - js-links —
<button onClick={router.push}>instead of<a href>. - click-reveal — main content hidden until user clicks.
- js-fetched — content fetched from
/api/...client-side. - hash-routing — fragment URLs (
#/path) instead of real paths. - late-loaded — IntersectionObserver-gated.
- mixed — realistic combination of the above.
Each pattern is tested across five page types (homepage, article, category, product, search) inside SSR, with CSR as the negative control and an optional SSG sanity check. That’s about 55 cells total — down from the 144 I would have needed for the mode experiment, and each cell answers a specific question instead of replicating a known result.
The cells are live now at next.jsseo.dev. Pick any URL, view source, and you can see the pattern at work — for the js-images cells, every <img> tag in the initial HTML has no src attribute at all (React 19 omits it because the state is an empty string). A crawler without JS execution gets <img> tags with nothing to fetch.
What survival actually means
The next question — the one I haven’t answered yet and which this whole project exists to answer — is: per pattern, what fraction of bot visits result in the bot actually seeing the content?
The tracker at track.jsseo.dev logs every hit. The aggregated rollup is at jsseo.dev/dashboard. What it shows right now is hit counts: GPTBot visited the js-fetched/homepage cell N times, Googlebot M times, ClaudeBot K times. That’s coverage. It’s not survival.
To get survival I need a second measurement: did the bot execute JavaScript on this specific visit? Without that, “GPTBot hit the page 47 times” tells me nothing about whether GPTBot saw the body or just the loading placeholder.
The mechanism is now a dual-beacon setup. V1 is an inline script that sends an image-shaped request through /api/js-executed; V2 is a React client component that sends a fetch() POST through /api/js-executed-v2. Bots that execute enough JavaScript to fire either beacon produce a Layer 3 row; bots that don’t, don’t. The tracker joins beacon events with hit rows by the per-cell marker UUID, with the beacon source kept visible because different bot sandboxes block different delivery mechanisms.
That measurement has landed, but it is still an instrument, not magic. A beacon proves that a specific beacon path fired; the interpretation still has to account for blocked network primitives, duplicate dual-beacon rows, and bot-specific sandbox behaviour.
What I’m doing differently this time
A few decisions I made when I rebuilt the experiment that I think matter:
Pre-registered hypotheses. Six of them, committed to the repo before any v0.4 data was collected (methodology page and METHODOLOGY.md have the full list). H3 is the main test — that patterns 2 through 7 produce invisible main content to batch crawlers. H5 is the watched one — that on-demand fetchers (ChatGPT-User, Claude-User, Perplexity-User) might behave differently from their batch siblings (GPTBot, ClaudeBot, PerplexityBot). I have no strong prior on H5. That’s the interesting one.
Open from day one. Source code at github.com/Qbeczek1/jsseo-dev. Raw tracker data published in the repo under data/. Test bed source under apps/next/. Tracker server source under tracker-server/. CC0 for data, MIT for code, CC-BY for prose. Anyone can replicate this on their own framework.
Bot verification before claims. Twenty-seven bot classes recognised, with reverse DNS for Google / Bing / Apple and published IP-range manifests for OpenAI / Perplexity. Current Anthropic crawler classes have no reliable public crawler IP list or stable rDNS suffix, so their UA claim remains unresolved rather than verified. Pre-2024 deprecated UAs (anthropic-ai, Claude-Web) auto-flagged unverified on insert. Numbers from claimed-but-unverified UAs are visibly separated in the dashboard so the analysis can filter them out.
Tracker truncated for clean baseline. The 700-odd hits collected during the mode-axis phase plus all of my own smoke-test traffic got wiped today before Sprint 4 starts. The dashboard you see is the first v0.4 data only. By the time real findings posts land, the baseline period will be uncontaminated.
What’s next on this site
This is the first post. The next ones will be data-anchored, with Layer 3 data interpreted alongside the source split between the two beacon delivery mechanisms.
Subscribe to the RSS feed if you want to know when new findings land. Or follow on LinkedIn (/in/jakubsawa) — I’ll cross-post highlights.
If you’re running this kind of experiment on your own framework, or you just want to discuss methodology, feel free to reach out at hello@fratreseo.com.
The infrastructure is done. The measurement is starting. Let’s see what survives.